导言:随着网络技术的飞速发展,半结构化、非结构化的文字信息已占网络信息的绝大部分,因此,对文本信息的处理与分析已成为网络技术和网络信息结构的一个重要课题。但非结构化文本信息不同于结构化文本信息,它不存在显式的结构,也没有明确的机制进行读写分析。针对结构化文本信息已经存在成熟的分析工具,但用于挖掘非结构化文本信息的分析工具正处于萌芽和发展阶段。
研究背景及意义
自然语言处理是计算机科学、人工智能、语言学的一个重要分支,其目的在于让电脑可以类似人类那样理解语言。但是,人类的语言是一种复杂的符号体系。电脑在处理和分析人类的语言时,会碰到很多问题:
(1)词汇量
自然语言中有大量的词汇量。在程序设计语言中,可以使用的关键字数目是有限制的,并且是固定的。尽管我们可以随意取变量名、函数名和类名,但是它们仅仅是为了区分而起的,它们并没有包含任何意义上的信息,并且不会对程序的编译和执行产生任何影响。但是,在自然语言中,我们能用到的词语却是数不胜数,而且几乎没有一个词是完全一样的。《现代汉语常用词表(草案)》列举了56008个现代汉语常用词汇,此外,每时每刻都有新的词汇诞生。
(2)结构化
自然语言是半结构化或非结构化的。结构化是指信息具有明确的结构关系。例如,编程语言中的类和成员以及数据库中的表和字段具有清晰的结构关系,可以通过一定的机制进行读写。然而,在自然语言中并没有这种明确的结构。即使是最简单的句子,计算机也很难正确理解它。
(3)歧义性
自然语言含有大量歧义。例如,汉语中的多义词,只有根据上下语境才能确定其含义;还有一些人运用一字多义、同形异义来构造双关,从而实现了句子的双重含义。这些不同情境的使用就使得机器很难理解语义。
由于自然语言本身的复杂性,自然语言处理一直是一个艰深的课题。近年来,自然语言处理技术发展迅猛,而且应用也日益广泛。在应用神经网络技术以前,自然语言的研究已经由规则化发展为统计化,而且深度学习的应用也加快了自然语言处理的发展。
随着互联网技术的不断发展,在互联网信息中,半结构化或非结构化的文本信息占据了绝大多数部分,文本信息的管理和分析成为互联网技术的研究热点,也是研究互联网信息结构的必经之路。
国内外研究现状及趋势
句子级的语义分析关注的是事件的特征,例如确定“谁”对“谁”、“哪里”、“何时”和“如何”做了“什么”。句子的谓语确定了“发生了什么”,而其他句子成分则表达了事件的参与者(例如“谁”和“哪里”),以及进一步的事件属性(例如“何时”和“如何”)。这时候就需要进行语义角色标注(Semantic Role Labeling,SRL)。
语义角色标注是从Fillmore(1968)年提出的格语法所出发的,但它并没有深入地分析句子中的语义信息,是一种浅层的语义分析技术。具体而言,语义角色标注的工作以语句中的谓词为中心,考察语句中的各个要素和谓词的关系,以及通过语义角色来描述它们之间的关系。
如图 1 所示,传统SRL主要有以下几个步骤:

(1)候选论元剪除,即把不能作为论元的词语从语句中剔除,一般是以规则为基础的,例如遍历语法树、句法依存树等方法;
(2)论元辨识,指从候选论元中识别出所有属于该谓词的论元,一般看作二值分类问题,采用SVM或者最大熵分类等方法;
(3)论元标注,指对识别出的论元赋予语义角色,一般看作多值分类问题;
(4)后处理,是指对识别结果的进一步处理,例如:删除在语义上的重叠的论元等。
传统的SRL算法的性能对特征工程要求较高,对领域知识和特征抽取都有很大的要求;并且在提取出复杂的特征时,很难对语句中的长距离依赖关系进行建模;
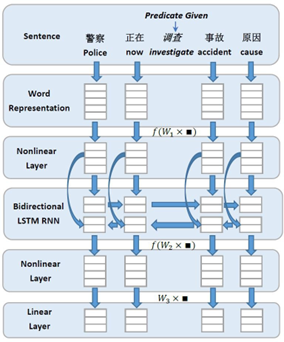
在深度学习占领了自然语言处理领域之后,基于深度学习的SRL方法也得到了广泛应用且效果良好。例如 Zhen Wang 等人提出了采用双向RNN的方法来进行中文语义角色标注,网络结构如图 2。
Zhen, W. , et al. “Chinese Semantic Role Labeling with Bidirectional Recurrent Neural Networks.” Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 2015.
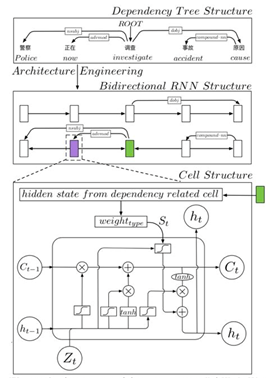
Feng Qian 提出将 Dependency Tree Structure 通过 Architecture Engineering 的方法(而非 Feature Engineering 的方法)放入到LSTM cell中,能够充分利用句子的句法依存结果提高结果,网络结构如图 d3。
Qian, F. , et al. “Syntax Aware LSTM model for Semantic Role Labeling.” Proceedings of the 2nd Workshop on Structured Prediction for Natural Language Processing, 2017.
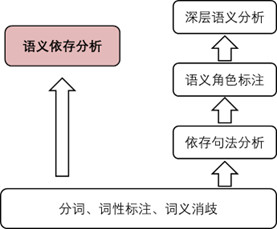
传统的语义分析方法是先进行分词、词性标注和词义消歧,然后是依存句法分析和语义角色标注,最后获得深层次的语义。但是因为每次分析都基于上一级的分析结果,错误级联效应会导致最终的分析结果精度很低,因此我们需要跨越句子表层句法结构的约束,直接获取深层语义信息。
语义依存分析(Semantic Dependency Parsing,SDP),是对句子中各个语言单元的语义联系进行分析,并以依赖关系呈现。利用依赖关系来表达句子的意义,其优势是无需对词语进行抽象,而可以利用词汇所承载的语义结构对词语进行描述,并且论元的数量比词汇少得多。语法结构对语义依存分析没有任何影响。在语义上有直接联系的语言单位将依存弧直接连接起来,然后用对应的语义联系来标注。
递归神经网络(Recursive Neural Network,RNN)在时序数据上表现出色,其中长短期记忆网络(Long Short-Term Memory,LSTM)为建模句子中词语之间的长距离依存创造了条件。
在语义依存分析任务中,Biaffine Attention依然是目前最准确的方法。
例如 Dozat 和 Manning 扩展了自己在2017基于LSTM的句法分析器,使用 Biaffine+Char+Lemma,训练和生成图结构,由此产生的系统本身就达到了最先进的性能,以0.6%的标记F1击败了之前的、复杂得多的最先进系统,模型结构如图 5 所示。
Dozat, Christopher D.. “Simpler but More Accurate Semantic Dependency Parsing.” Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Association for Computational Linguistics, 2018.
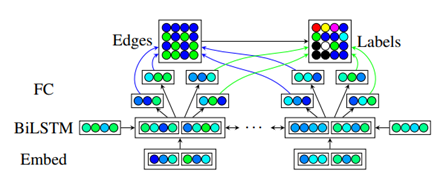
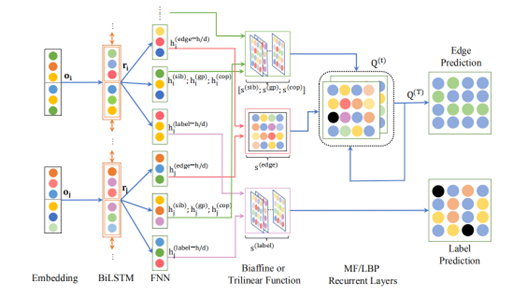
Wang 提出了一个二阶语义依存关系解析器,它不仅考虑了单个依存关系的边缘,还考虑了成对边缘之间的相互作用。二阶解析可以使用均值场(MF)变异推理或循环信念传播(LBP)进行近似,于是将这两种算法作为神经网络的递归层展开,可以以端到端的方式训练解析器,模型结构如图 6 所示。
Wang, Kewei. “Second-Order Semantic Dependency Parsing with End-to-End Neural Networks.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2019.
自然语言处理任务的层次
自然语言处理的基本层次如图 7 所示:
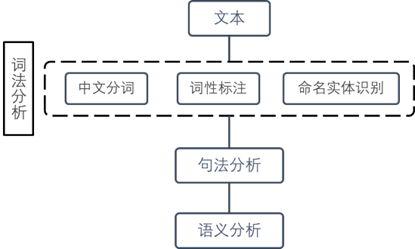
词法分析
对词汇进行的解析被称为词法分析。词法分析的首要工作就是把文字划分为有意义的词语(分词),并对其进行分类(词性标注),以及对专有名词进行鉴别(命名实体识别)。词法分析经常是以后更高层次的工作的基础。词法上的错误,会对后面的工作造成很大的影响。
经过词汇学分析,文章出现了局部结构化的倾向。电脑不再接受复杂的文字,它会接受一系列有意义的词语,并且每一个词语都带有词性和其它标记。
根据这些词语和标记,我们可以提取一些有用的信息,从比如使用算法提取出关键词,还可以根据词与词之间的统计信息提取关键短语甚至句子。
将文本拆分为一系列词语之后,我们还可以在文章级别做一系列分析,例如文本分类和文本聚类。
句法分析
词法分析仅能获取零星的词语信息,而电脑对这些词间的联系却一无所知。在某些问答系统中,如果要确定句子的主谓宾语,则要对其进行句法分析。语法分析不仅仅适用于问答和搜索引擎,也广泛用于基于词组的机器翻译,为译文中的词汇进行重新排列。
语义分析
相对于句法分析,语义分析更注重语义的研究。它包含了词义消歧(决定词汇在具体上下文中的意义)、语义角色标记(标记语与语句中其他元素的关系)以及语义依赖性分析(语义关联分析)。
CRF
条件随机场(Conditional Random Field,CRF)是Lafferty等人首先提出的一种无向图模型,他们认为条件随机场比隐马尔可夫模型(Hidden Markov Model,HMM)和随机语法有不少优势,例如可以使这些模型中的强独立性得到放宽。同时CRF克服了最大熵马尔可夫模型(Maximum Entropy Markov Model,MEMMs)以及其它基于有向图的马尔可夫模型的局限性,据此他们提出了CRF的迭代参数估计算法,并比较了所得模型与HMMs和MEMMs的性能。
Lafferty J , Mccallum A , Pereira F C N . Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data[J]. proceedings of icml, 2002.
Peng等人首次使用CRF用于中文分词,将其视为一项二元决策任务,使用高斯先验来防止过度拟合,使用准牛顿方法来做优化参数。
Peng F , Feng F , Mccallum A . Chinese segmentation and new word detection using conditional random fields. Association for Computational Linguistics, 2004.
CRF为一个特定的字符序列分配标签序列的概率公式如下: \(P_λ (Y│X)=\frac{1}{Z(X)} exp(\sum_{cϵC}^{}{}\sum_{k}^{}{λ_kf_k(Y_c,X,c)}\)
其中,$Y$是句子的标签序列,$X$是未分割的字符序列,$Z(X)$是一个归一化项,$f_k$是一个特征函数,$c$索引到序列中被标记的字符。
CRF允许我们利用大量的n-gram特征和基于不同状态序列的特征,可用于完成自然语言处理中的分词、词性标注、命名实体识别等任务。
BERT
BERT的基本原理
BERT(Bidirectional Encoder Representations from Transformers)是谷歌团队在2018年提出的一种新的语言模型。
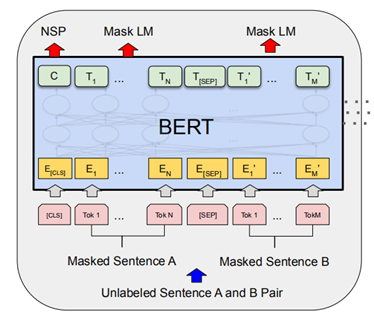
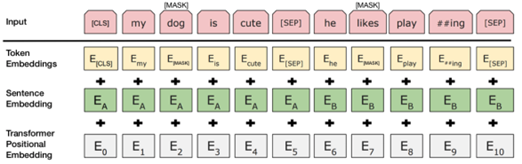
由图 8 可知,BERT采用Transformer的注意力机制,BERT主体由多个Transformer叠加在一起,能够了解并且学习文本中词语间的上下文关系。Transformer的初始形式包含两种不同的机制:用于读取文本的编码器和生成预测的解码器。BERT使用其中的编码器来生成语言模型。
与顺序读取文本输入的方向模型相反,Transformer编码器一次读取整个词语序列的特点,让模型可以根据周围语境学习词语的上下文。
BERT的训练策略
BERT使用两种训练策略:
(1)Masked Language Model (MLM)
在把一个词语序列输入到BERT之前,用[MASK]标记取代了15%的词语。然后,模型将尝试通过序列中其它没有被隐藏的词语所提供的上下文信息,来判断被隐藏的词语的初始值。
(2)Next Sentence Prediction (NSP)
在BERT的训练过程中,模型会接收成对的句子作为输入,并学习预测第二个句子是不是原始输入中的后续句。在训练过程中,50%的输入是一对句子,其中第二句是原始输入中的后续句子,而另外50%的输入则是从语料库中随机选择一个句子作为第二句。
为了帮助模型在训练中区分这两个句子,在进入模型之前对输入进行一定处理:在第一个句子的开头插入一个[CLS]标记,在每个句子的末尾插入一个[SEP]标记;为每一个token表征都添加一个embedding来指示其属于句子A还是句子B。